Compute Shader
컴퓨트 쉐이더는 GPU에게 연산 일을 시키는 작업
General Purpose Computing On Graphics Processor Units
줄여서 GPGPU를 통해 병렬로 연산을 처리하기 위해 사용합니다.
간단한 예시 하나 들자면
CPU는 수학과 교수님이 어려운 문제를 계속 푸는 거라면
GPU는 초등학생 100명에게 간단한 수학 문제를 풀게 만드는 겁니다.
유니티에서 예를 들면 수십 수백만 개의 오브젝트의
위치를 계산할 때라든지 간단하지만 많은 작업을 할 때 사용합니다.
Compute Shader
Unity 6을 사용했습니다.
생성
우선, Compute Shader를 생성해야 합니다.
생성 방법은 아주 간단한데
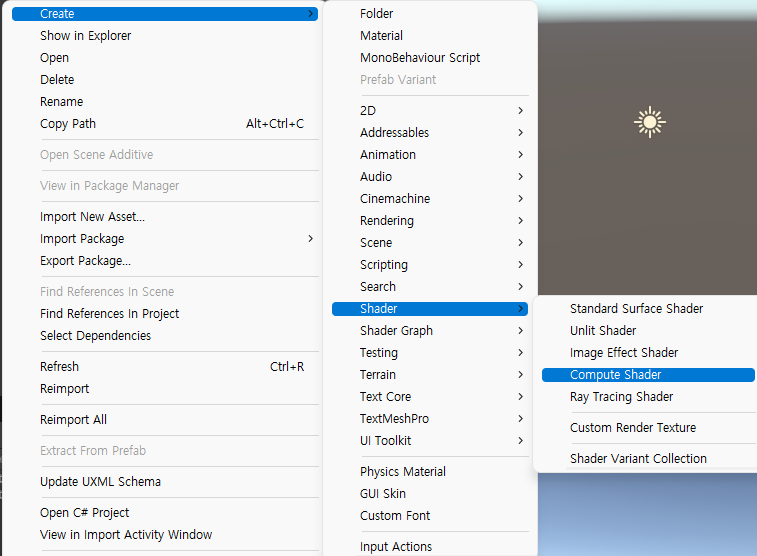
위 경로로 가셔서 Compute Shader를 생성하면 됩니다.
그러면

이런 식으로 확장명이 compute인 파일이 생성됩니다.
Compute Shader 구조

compute 파일을 열어보면 위 사진과 같은 코드가 나옵니다.
참고로 Compute Shader는 DirectX에서 사용하는 HLSL 언어를 사용합니다.
kernel

kernel은 함수의 이름이라고 생각하면 됩니다.
보통 코드 최상단에 위치하고
#pragma kernel '함수명' 이렇게 적은 다음

함수의 몸체는 따로 정의합니다.
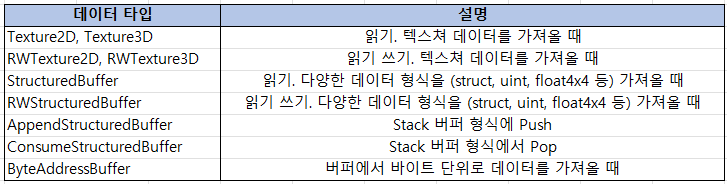
type

이 부분은 CPU에서 2D 이미지를 가져올 때 사용하는 변수입니다.
타입이 float4라고 적혀있는데 보통 이미지는 RGBA 형식으로 가져와서
이미지 포맷에 맞추기 위해 float4를 사용합니다.

그래서 Result에 float4를 넣는 것을 볼 수 있습니다.
numthreads

numthreads(8,8,1)
이렇게 적혀있는데 8, 8, 1 각각 x, y, z를 뜻하고
x는 1차원, y는 2차원, z는 3차원을 뜻하기도 합니다.


numthreads(8,8,1)와 numthreads(64,1,1)은 사용하는 스레드 수는 같지만
차원이 다르다는 차이점이 있습니다.
그럼 차원을 왜 나누냐?
| 차원 | 사용 |
| 1 | 배열, 리스트, 정렬 같이 입력 데이터가 1차원인 경우 |
| 2 | 2D 이미지나 텍스쳐 같이 입력 데이터가 2차원인 경우 |
| 3 | 3D 공간 같이 입력 데이터가 3차원인 경우 |
각 차원마다 사용 용도가 다르기 때문에 차원을 나눈다고 합니다.
Thread Group과 Thread Index
Thread Group
아까 numthreads(8,8,1)을 기준으로
8 * 8 = 64개의 스레드가 모여 1개의 Thread Group을 이루게 되는데
Thread Group도 여러 개가 될 수 있습니다.
public class ObjectPosition : MonoBehaviour
{
[SerializeField]
private ComputeShader shader;
private int csMainKernel;
private void Start()
{
// 커널 찾기.
csMainKernel = shader.FindKernel("CSMain");
// 텍스쳐 생성.
RenderTexture tex = new RenderTexture(256, 256, 24);
tex.enableRandomWrite = true;
tex.Create();
int groupX = Mathf.CeilToInt(tex.width / 8.0f);
int groupY = Mathf.CeilToInt(tex.height / 8.0f);
int groupZ = 1;
// 커널에 텍스쳐 전달.
shader.SetTexture(csMainKernel, "Result", tex);
shader.Dispatch(csMainKernel, groupX, groupY, groupZ);
}
}
맨 밑에 Dispatch 부분에 256 / 8, 256 / 8, 1 이 인수 부분들을 보겠습니다.
RenderTexture를 생성할 때 Width 256, Height 256 이렇게 생성했습니다.
texture에는 x 방향으로 데이터가 256개 y 방향으로 256개가 있겠죠?
그리고 256 * 256 = 65536개의 데이터들로 이루어진 Texture를 SetTexture를 통해 GPU로 넘겨줍니다.
여기서 SetTexture의 "Result"는 아까 RWTexture2D 변수입니다.
그리고 Dispatch를 통해 커널을 실행합니다.
Dispatch에서
2번째 ~ 4번째 인수는 그룹의 개수입니다.
int groupX = Mathf.CeilToInt(tex.width / 8.0f);
int groupY = Mathf.CeilToInt(tex.height / 8.0f);
int groupZ = 1;
여기서 x는 256 / 8 = 32
(x 데이터 개수 = 256 / numthreads의 x = 8)
y는 256 / 8 = 32
(y 데이터 갯수 = 256 / numthreads의 y = 8)
z는 1
Thread Group는 (32, 32, 1)입니다.
아까 numthreads는 8,8,1 이였으니까
(32 * 8) * (32 * 8) * (1 * 1) = 65536개의 스레드를 사용하게 됩니다.
아까 데이터 개수와 똑같죠?
굳이 이렇게 맞아떨어지게 계산하는 이유는 스레드가 낭비되는 것을 막기 위해서입니다.
스레드가 데이터 개수보다 작으면 오류가 뜨지만
많다고 해서 오류가 뜨진 않습니다.
근데 groupX, groupY에 올림 해주는 CeilToInt는 왜 붙은 걸까요?
1차원 데이터 29538 가 있다고 가정해 보겠습니다.
그리고 numthreads는 32, 1, 1 이렇게 정하겠습니다. 1차원이니 y, z는 1입니다.
그러면 Thread Group의 x 개수는 29538 / 32 하면 923.0625 가 나옵니다.
thread나 thread group은 무조건 1 이상인 양의 정수여야 합니다.
그렇다고 923이라고 thread X 개수를 적으면 923 * 32 = 29536으로 데이터 개수보다 적기 때문에 오류가 발생합니다.
그래서 CeilToInt를 써서 올려버리면 924 * 32 = 29,568
데이터 개수보다 많은 스레드를 쓰지만 오류 안 뜨게 하는 최선의 방법입니다.
정리하자면
1. Thread Group (Dispatch) 안에 Thread (numthreads) 들이 있다.
2. 차원에 따라 사용 용도가 다르다.
3. 가져올 데이터보다 thread 개수가 적어선 안된다.
SV_GroupThreadID
thread 또는 thread group의 index를 가져오는 방법도 있습니다.

일반적으로 SV_DispatchThreadID, SV_GroupThreadID, SV_GroupID, SV_GroupIndex
이렇게 4개가 있습니다.
#pragma kernel CSMain
#define NUM_THREADS 8
RWStructuredBuffer<uint> NumBuffer;
[numthreads(NUM_THREADS,1,1)]
void CSMain (uint3 tid : SV_DispatchThreadID, uint3 gtid : SV_GroupThreadID)
{
NumBuffer[tid.x] = gtid.x;
}
SV_GroupThreadID는 각 Thread Group에서 개별 index를 가집니다.

위 코드에서 numthreads x가 8이니까
한 Thread Group 마다 0 ~ 7이 출력됩니다.
NumBuffer[gtid.x] = gtid.x 이렇게 하면
NumBuffer[0] = 0
NumBuffer[1] = 1
.
.
NumBuffer[7] = 7
NumBuffer[0] = 0
NumBuffer[1] = 1
.
.
NumBuffer[7] = 7
즉, numthreads의 개수에 따라 숫자가 반복됩니다.
gtid의 데이터 타입이 uint3인 이유는
numthreads의 차원에 따라서 데이터를 가져오는 방법이 다르기 때문입니다.
위 코드는 1차원이니까 gtid.x로 했지만
2차원이면 gtid.xy
3차원이면 gtid.xyz
이런 식으로 가져와야 합니다.
SV_GroupID
SV_GroupID는 0~그룹 개수만큼 index가 정해집니다.
#pragma kernel CSMain
#define NUM_THREADS 8
RWStructuredBuffer<uint> NumBuffer;
[numthreads(NUM_THREADS,1,1)]
void CSMain (uint3 gid : SV_GroupID)
{
NumBuffer[gid.x] = gid.x;
}
예를 들어 NumBuffer의 크기가 65536이고 1차원이면 Thread Group의 개수는 (8192, 1, 1) 이 됩니다.
그러면 위 코드는
NumBuffer[0] = 0
NumBuffer[1] = 1
.
.
.
NumBuffer[8191] = 8191
이런 식으로 index가 정해집니다.
groupID도 uint3 이므로 차원에 따라 달라집니다.
SV_DispathThreadID
SV_DispatchThreadID는
예를 들어 65536개의 스레드가 있으면
그냥 0 ~ 65535까지의 index를 가져옵니다.
#pragma kernel CSMain
#define NUM_THREADS 8
RWStructuredBuffer<uint> NumBuffer;
[numthreads(NUM_THREADS,1,1)]
void CSMain (uint3 tid : SV_DispatchThreadID)
{
NumBuffer[tid.x] = tid.x;
}
이 코드를 보면 NumBuffer[0] = 0
NumBuffer[1] = 1
NumBuffer[2] = 2
.
.
.
NumBuffer[65535] = 65535
이런 식으로 스레드 개수만큼 가져옵니다.

굳이 더 자세히 설명하자면
[(GroupID) * (Thread Group Count)] + GroupThreadID라고 하는데
위에 2번째 Thread Group 안에 있는 11을 예로 들면
[(1, 0, 0) * (8, 0, 0)] + (3, 0, 0) = (11, 0, 0)
이렇게 DispatchThreadID가 정해집니다.
제가 1 Thread Group, 2 Thread Group이라고 적어놓긴 했는데
thread나 thread group 모두 0부터 시작합니다.
SV_GroupIndex
SV_GroupIndex는 SV_GroupID를 1차원으로 바꿔서 index를 정해줍니다.
Thread Group이 (8, 8, 1) 이면
GroupID는 x는 0~7, y는 0~7, z는 0
이런 식으로 출력되는데
SV_GroupIndex는 0부터 15까지 출력하게 됩니다.
C# Script 구조
#pragma kernel CSMain
#define NUM_THREADS 32
RWStructuredBuffer<uint> NumBuffer;
[numthreads(NUM_THREADS,1,1)]
void CSMain (uint3 tid : SV_DispatchThreadID)
{
NumBuffer[tid.x] = tid.x;
}
이 Compute Shader를 기준으로 설명하겠습니다.
public class ObjectPosition : MonoBehaviour
{
[SerializeField]
private ComputeShader shader;
private ComputeBuffer numBuffer;
private int[] numDatas;
private int csMainKernel;
private readonly int count = 65536; // 총 65536개의 데이터를 생성.
private readonly int threadX = 32;
private void Start()
{
csMainKernel = shader.FindKernel("CSMain"); // 커널 찾기.
numBuffer = new ComputeBuffer(count, sizeof(int)); // count는 데이터의 개수, sizeof(int)는 데이터의 크기.
numDatas = new int[count];
int groupX = Mathf.CeilToInt(count / (float) threadX);
int groupY = 1;
int groupZ = 1;
shader.SetBuffer(csMainKernel, "NumBuffer", numBuffer); // 컴퓨트 쉐이더에 버퍼를 전달.
shader.Dispatch(csMainKernel, groupX, groupY, groupZ); // 커널 실행.
numBuffer.GetData(numDatas); // 버퍼에서 데이터를 가져옴.
for (int i = 0; i < count; i++)
{
Debug.Log(numDatas[i]);
}
}
}
이 스크립트는 SV_DispatchThreadID가 실제로 어떤 index 값을 가져오는지 보기 위한 코드입니다.
1. 우선 Compute Shader를 가져옵니다.
2. 커널을 찾습니다.
커널은 위에서 아래로 선언된 순서에 따라 0, 1, 2, 3 ... int 형으로 정해집니다.
3. Compute Buffer를 만들어줍니다.
Compute Buffer는 CPU와 GPU 간 데이터를 전송할 수 있는 그릇이라고 생각하면 됩니다.
ComputeBuffer의 첫 번째 인수는 데이터 개수, 두 번째 인수는 stride라고 하는데
데이터의 타입을 sizeof로 넣어주면 됩니다.
4. Compute Shader에 Compute Buffer를 할당합니다.
5. Dispatch로 커널을 실행합니다.
6. GPU에서 numBuffer에 계산한 결과를 넣었으니
이제 CPU에서 GetData를 통해 결과 값들을 가져옵니다.
'유니티 > Tutorial' 카테고리의 다른 글
| Unity 디자인 패턴 Observer (0) | 2025.04.25 |
|---|---|
| Unity 디자인 패턴 Singleton (0) | 2025.04.07 |
| Unity New Input System (0) | 2025.02.19 |
| Unity FSM 유한 상태 머신 (0) | 2025.01.13 |
| UniTask란? (0) | 2025.01.09 |